For 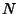 samples of a variate having a distribution with known Mean
samples of a variate having a distribution with known Mean 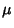 , the ``population
variance'' (usually called ``variance'' for short, although the word ``population'' should be added when needed to
distinguish it from the Sample Variance) is defined by
, the ``population
variance'' (usually called ``variance'' for short, although the word ``population'' should be added when needed to
distinguish it from the Sample Variance) is defined by
where
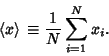 |
(2) |
But since
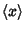 is an Unbiased Estimator for the Mean
is an Unbiased Estimator for the Mean
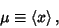 |
(3) |
it follows that the variance
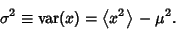 |
(4) |
The population Standard Deviation is then defined as
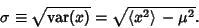 |
(5) |
A useful identity involving the variance is
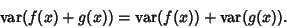 |
(6) |
Therefore,
If the population Mean is not known, using the sample mean 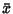 instead of the population mean to
compute
instead of the population mean to
compute
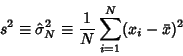 |
(9) |
gives a Biased Estimator of the population variance. In such cases, it is appropriate to use a
Student's t-Distribution instead of a Gaussian Distribution. However, it turns out (as discussed
below) that an Unbiased Estimator for the population variance is given by
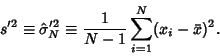 |
(10) |
The Mean and Variance of the sample standard deviation for a distribution with population mean and
Variance are
The quantity
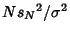 has a Chi-Squared Distribution.
has a Chi-Squared Distribution.
For multiple variables, the variance is given using the definition of Covariance,
A linear sum has a similar form:
These equations can be expressed using the Covariance Matrix.
To estimate the population Variance from a sample of elements with a priori unknown Mean (i.e.,
the Mean is estimated from the sample itself), we need an Unbiased Estimator for 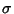 . This is
given by the k-Statistic
. This is
given by the k-Statistic 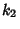 , where
, where
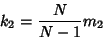 |
(15) |
and 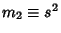 is the Sample Variance
is the Sample Variance
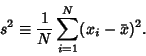 |
(16) |
Note that some authors prefer the definition
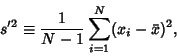 |
(17) |
since this makes the sample variance an Unbiased Estimator for the population variance.
When computing numerically, the Mean must be computed before 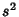 can be determined. This requires storing the set of
sample values. It is possible to calculate
can be determined. This requires storing the set of
sample values. It is possible to calculate 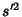 using a recursion relationship involving only the last sample as
follows. Here, use
using a recursion relationship involving only the last sample as
follows. Here, use 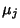 to denote calculated from the first
to denote calculated from the first 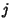 samples (not the th Moment)
samples (not the th Moment)
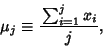 |
(18) |
and 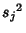 denotes the value for the sample variance calculated from the first samples. The first few
values calculated for the Mean are
denotes the value for the sample variance calculated from the first samples. The first few
values calculated for the Mean are
Therefore, for 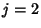 , 3 it is true that
, 3 it is true that
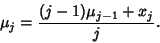 |
(22) |
Therefore, by induction,
and
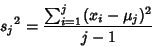 |
(26) |
for 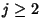 , so
, so
Working on the first term,
Use (24) to write
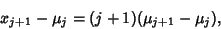 |
(29) |
so
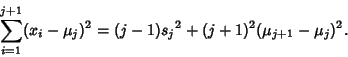 |
(30) |
Now work on the second term in (27),
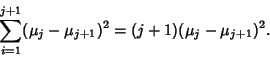 |
(31) |
Considering the third term in (27),
But
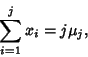 |
(33) |
so
Plugging (30), (31), and (34) into (27),
so
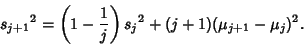 |
(36) |
To find the variance of itself, remember that
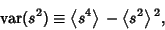 |
(37) |
and
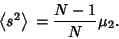 |
(38) |
Now find
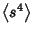 .
.
Working on the first term of (39),
The second term of (39) is known from k-Statistic,
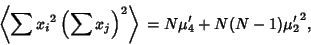 |
(41) |
as is the third term,
Combining (39)-(42) gives
so plugging in (38) and (43) gives
Student calculated the Skewness and Kurtosis of the distribution of as
and conjectured that the true distribution is Pearson Type III Distribution
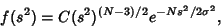 |
(47) |
where
This was proven by R. A. Fisher.
The distribution of 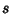 itself is given by
itself is given by
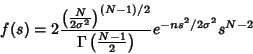 |
(50) |
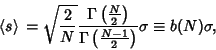 |
(51) |
where
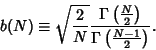 |
(52) |
The Moments are given by
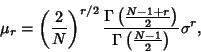 |
(53) |
and the variance is
An Unbiased Estimator of is 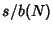 . Romanovsky showed that
. Romanovsky showed that
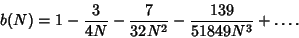 |
(55) |
See also Correlation (Statistical), Covariance, Covariance Matrix, k-Statistic, Mean,
Sample Variance
References
Press, W. H.; Flannery, B. P.; Teukolsky, S. A.; and Vetterling, W. T. ``Moments of a Distribution: Mean,
Variance, Skewness, and So Forth.'' §14.1 in
Numerical Recipes in FORTRAN: The Art of Scientific Computing, 2nd ed. Cambridge, England:
Cambridge University Press, pp. 604-609, 1992.
© 1996-9 Eric W. Weisstein
1999-05-26
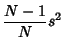
![$\displaystyle {N-1\over N^3} [(N-1)\mu_4-(N-3){\mu_2}^2].$](v_182.gif)
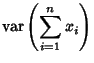
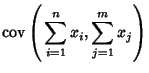
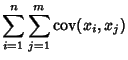
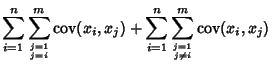
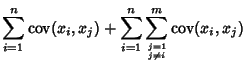
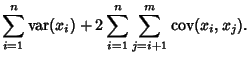
![$\displaystyle {[(j+1)-1]\mu_{(j+1)-1}+x_{j+1}\over j+1}$](v_214.gif)
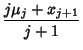
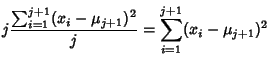
![$\displaystyle \sum_{i=1}^{j+1} [(x_i-\mu_j)(\mu_j-\mu_{j+1})]^2$](v_223.gif)
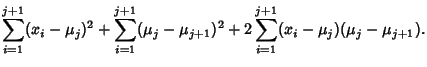
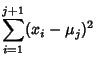
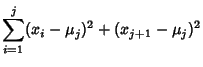
![$\displaystyle \left\langle{\left[{{1\over N}\sum {x_i}^2-\left({{1\over N} \sum x_i}\right)^2}\right]^2}\right\rangle{}$](v_251.gif)
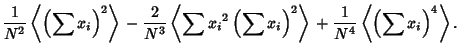
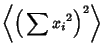
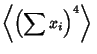
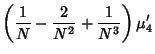
![$\displaystyle +\left[{{N-1\over N}-{2(N-1)\over N^2}+{3(N-1)\over N^3}}\right]{\mu'_2}^2$](v_265.gif)
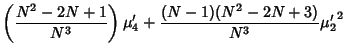
![$\displaystyle {(N-1)[(N-1)\mu'_4+(N^2-2N+3){\mu'_2}^2]\over N^3},$](v_267.gif)
![$\displaystyle {(N-1)[(N-1)\mu'_4+(N^2-2N+3){\mu'_2}^2]\over N^3}-{(N-1)^2N\over N^3}{\mu'_2}^2$](v_270.gif)
![$\displaystyle {N-1\over N^3} \{(N-1)\mu'_4+[(N^2-2N+3)-N(N-1)]{\mu'_2}^2\}$](v_271.gif)
![$\displaystyle {(N-1)[(N-1)\mu'_4-(N-3){\mu'_2}^2] \over N^3}.$](v_272.gif)
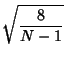

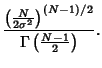
![$\displaystyle \nu_2-{\nu_1}^2 = {N-1\over N} \sigma^2-[b(N)\sigma]^2$](v_288.gif)
![$\displaystyle {1\over N} \left[{N-1-{2\Gamma^2\left({{\textstyle{N\over 2}}}\right)\over \Gamma^2\left({{\textstyle{N-1\over 2}}}\right)}\sigma^2}\right].$](v_289.gif)